Learning Machine Learning

Professional Services Team Lead
AWS Solutions Architect
Well Architected Team Lead
Certs:
AWS Certified Solutions Architect - Professional
AWS Certified DevOps Engineer - Professional
AWS Certified Solutions Architect – Associate
AWS Certified Developer - Associate
AWS Certified Cloud Practitioner
ITIL v3 Foundation
SVQ 3 Management
I'm in the process of working through some Machine Learning Training at the moment, with the aim of taking the AWS Machine Learning Speciality Exam and I've had some thoughts on Machine Learning training and learning as a whole that I'd like to share.
Machine Learning Scope
Machine Learning is a huge topic, and one of the struggles I had initially was just understanding the scope of the topic and where what I was trying to learn fit into the scope. There is a huge number of areas of research and tools to use, that it can be hard to decide where to start, and sometimes it's a bit of a rabbit hole once you do start learning a particular topic.
Just on AWS, the number of services used is huge, take this infographic for example, from the Practical Data Science on AWS book:
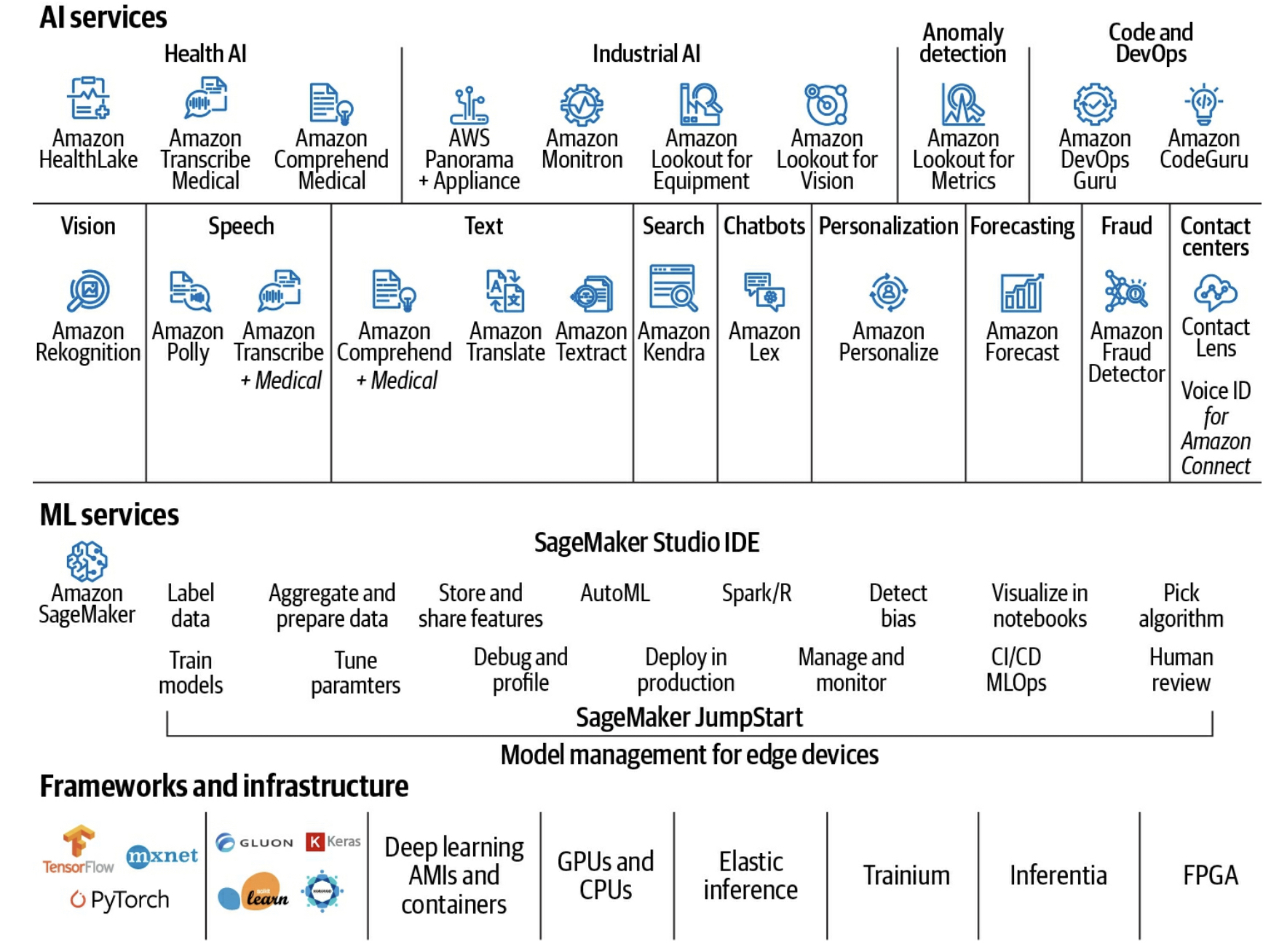
Knowing which service to pick to look at initially can be daunting.
A practical approach
The approach I've tried to take with my Machine Learning Journey is to learn it in stages, with the higher-level tasks first, then going deeper into specific areas. I've jumped around a bit, due to the nature of the exam I'm aiming for, so I've not followed this exactly, but I think this approach is a practical one.
- Learn services that utilize Machine Learning, but don't require Machine Learning knowledge on the end-users part. This will gain you an understanding of what is possible.
- Learn Data Analysis tools and methods. Often you'll be able to gain insights just from a standard analysis that can be immediately useful, and then can be further enhanced by Machine Learning.
- Learn common Machine Learning model methods. At this point, don't go too deep into how something works, but learn how to use the different methods and what's required as input/output.
- Learn how to analyse Machine Learning models, and what the different metrics mean, such as when accuracy or recall is better for a specific situation and what the F1 score can tell you about how well the model is performing.
- Learn how to Deploy Machine Learning Models and the typical Machine Learning workflows.
- Learn more about your chosen model methods, how they work in the background and the ways you can get the most out of them.
- Learn more in-depth about how the actual model code is created and the code behind it.
- Develop your own implementation of a common use case, like K-Nearest-Neighbours. Not a complicated one, but writing the code to do one of the more common ones can teach you a lot.
- Use feedback loops to gather more data and improve your model's accuracy.
Terminology
This has been my own experience of trying to get to grips with Machine Learning, however, I do believe we need more people who can get up to the point of learning about Machine Learning and using it in production, without really the need for more in-depth understanding, so that the use of Machine Learning can spread.
It's good for people to understand what's happening under the hood, and to contribute to new models and methods of working, but I believe we need more people at the higher level of just actually using the Machine Learning tools, and providing value through their outputs as well.
However, I've found that a lot of the knowledge you need for Machine Learning isn't really detailed in a way that makes this process easy, it's set up so that you need to go deeper into how something works, just to properly understand the usage.
As an example, one of the classification algorithms is Latent Dirichlet Allocation or LDA. It's used for Topic Modelling/Discover, and grouping documents together. So for example, you might have 10 documents, 4 of which talk about Cats, and 6 of them talking about Dogs. While LDA runs, it will find all of the words that are similar in the Cats document and will likely end up creating a Topic showing they are linked, which you can then label as CAT_RELATED.
Using this algorithm is relatively straightforward in what you need to pass into it, and how to use what you get out (and how to measure performance), but if you were to look up the Wikipedia entry for it, it starts like this:
In natural language processing, the Latent Dirichlet Allocation (LDA) is a generative statistical model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar. For example, if observations are words collected into documents, it posits that each document is a mixture of a small number of topics and that each word's presence is attributable to one of the document's topics. LDA is an example of a topic model and belongs to the machine learning field and in a wider sense to the artificial intelligence field.
To someone with a background in Statistics, a lot of that likely makes sense, and when you go more in-depth to these types of algorithms, you will need to know a lot of what is being talked about here, but I'd argue for day-to-day usage of Machine Learning, this isn't as important.
Down the Rabbit Hole
With descriptions like the one above, I've found that I end up trying to understand all the related terms and background as described, and I end up sprawling through different articles and videos trying to get a base understanding.
To expand on the example above for LDA, this is the sort of click-through I would have done.
- Start on https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
- Wonder what a generative model is https://en.wikipedia.org/wiki/Generative_model
- Read about Generative vs Discriminative
- See Logistic Regression, realise that was mentioned in relation to XGBoost
- Read about Logistic Regression, go back a step to Linear Regression
- Read about Gradient Boosting
- Read about XGBoost in particular, wonder what Newton Raphson is.
- Read about newton raphson method
- Wonder what unobserved groups were https://en.wikipedia.org/wiki/Latent_variable
And so on. Before you know it, rather than just learning how to use LDA, you're deep in the weeds of statistics and looking at pages like this, when all you wanted was to classify some documents:
Resources
I've listed some resources I've found useful on my Machine Learning journey below. Some of them are specific to the Exam I'm looking at, but some are also general.
Machine Learning Practice Exams https://www.udemy.com/course/aws-certified-machine-learning-specialty-full-practice-exams/
AWS Certified Machine Learning Specialty 2021 - Hands On! https://www.udemy.com/course/aws-machine-learning/
Practical Data Science Specialization https://www.coursera.org/specializations/practical-data-science
Data Science on AWS book https://www.amazon.co.uk/Data-Science-AWS-End-End/dp/1492079391/
Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems https://www.amazon.co.uk/Hands-Machine-Learning-Scikit-Learn-TensorFlow/dp/1492032646/



