Elastic Compute Cloud: EC2 (Intro to AWS Series) Part 3

Professional Services Team Lead
AWS Solutions Architect
Well Architected Team Lead
Certs:
AWS Certified Solutions Architect - Professional
AWS Certified DevOps Engineer - Professional
AWS Certified Solutions Architect – Associate
AWS Certified Developer - Associate
AWS Certified Cloud Practitioner
ITIL v3 Foundation
SVQ 3 Management
Welcome to Part 3 of my EC2 section of my Intro to AWS series. This is a continuation of part 1 and part 2, which you can read here: https://blog.johnwalker.tech/elastic-compute-cloud-ec2-intro-to-aws-series
and here:
https://blog.johnwalker.tech/elastic-compute-cloud-ec2-intro-to-aws-series-part-2
In this post, I will continue with some topics I mentioned at the end of the last post.
Load Balancing
Load balancing is one of the key components of allowing your traffic that is destined for EC2 instances to be handled be multiple back-end servers. This allows you to have more than one server running your application while having a single point of entry for your traffic. The load is then routed evenly across all the target instances, so you don't overload any one specific server.
Load Balancers
There are 3 types of load balancers, depending on how you want to route your traffic and at what level of the request you wish to do the routing.
The levels refer to each level of the OSI Model: https://en.wikipedia.org/wiki/OSI_model which breaks down each request between a client and server into 7 levels.
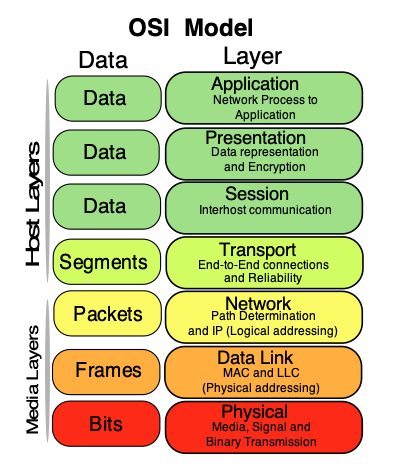 Image from https://commons.wikimedia.org/wiki/File:Osi-model-jb.svg
Image from https://commons.wikimedia.org/wiki/File:Osi-model-jb.svg
For the purposes of load balancing we are concerned with Levels 4 and 7. Level 4 operates at the Transport layer, which is concerned with the routing of traffic on the network. This generally allows you to route based on where the request is going, using information such as the IP Address or Port. This is usually low latency and can be quick at routing as it doesn't have to look at any of the application layer details.
At level 7, the load balancer is operating at the Application Level, so it will have access to more information about the request, such as headers, URL, and any other HTTP / HTTPS information.
Application Load Balancers
Application Load Balancers are the most common option people use as they offer the most flexibility and access to data about the request.
A basic setup for something like an Apache server would consist of routing HTTP requests to a target group of servers listening on port 80 and routing HTTPS requests to a target group listening on port 443. It's also common to redirect http requests to port 443 to upgrade any insecure requests to HTTPS, to ensure SSL is used at all times.
Application Load Balancers can also split up traffic based on how it arrives in. You might have a set of servers you want to run your search process, where the URLs come in with /search in the path, so you can route those to a specific set of servers, or even the same set of servers on a different port.
Network Load Balancers
Network Load Balancers run at an earlier level of the request process than Application Load Balancers, and as such can route without having to look at the full application request. If you only need routing based on ports, or you need a lot of traffic to run through the load balancer, then Network Load Balancers can be very useful. They are especially useful inside of your application where you are routing from one place to another so you are more in control of the routing request coming into the load balancer. This is useful for containerised applications and similar structures.
Classic Load Balancers
Classic Load Balancers are the older type that AWS supported. They can still be created, but don't have as much functionality as the other 2 types. It's recommended to use either an Application Load Balancer or a Network Load Balancer, unless you specifically need to use the old style EC2-Classic.
A comparison of the feature sets is available here: [https://aws.amazon.com/elasticloadbalancing/features/#Product_comparisons] (https://aws.amazon.com/elasticloadbalancing/features/#Product_comparisons)
Target Groups
Target groups are how Load Balancers know where to send traffic after matching one of the rules you have set up (such as forwarding port 443 traffic). Each Target Group can contain one or more servers and is set up with health checks to ensure the instances are listening and are ready to serve traffic.
When an instance is added or removed, the instance is removed from the Target Group initially so it gets no more traffic, then waits until any existing traffic is drained from it, then it is removed or terminated.
Scaling
Scaling is a key topic to getting the most out of AWS. One of the main reasons AWS and Cloud computing in general is different from typical on premise solutions is that you only pay for what you use, and to minimise your usage, you can turn servers on and off so they are only available when you need them, and you can scale up and down in response to your usage, so you only have more resources available when you need it.
Vertical vs Horizontal Scaling
Scaling can be thought of in 2 ways, vertical and horizontal. Vertical scaling refers to changing a specific instance from one size to another. So, for example, if you had an M4.large and changed it to an M4.xlarge, that would be vertically scaling that instance.
Horizontal scaling is scaling out the way, and usually refers to adding more instances, to something like an auto scaling group (or just adding more servers to a target group). Adding more servers gives you more capacity to deal with traffic, and you can remove the capacity when it's no longer needed.
Features such as Auto Scaling Groups allow you to replicate the same instance multiple times and shut them down when needed.
Launch Configurations
When you create a new server to horizontally scale, you can create a Launch Configuration to tell amazon what type of server you want, what AMI to use to create it, what security groups it should be in and more. This launch config allows you to define exactly what type of server should be scaled up and pre-configure it to be set up as you need it.
Auto Scaling
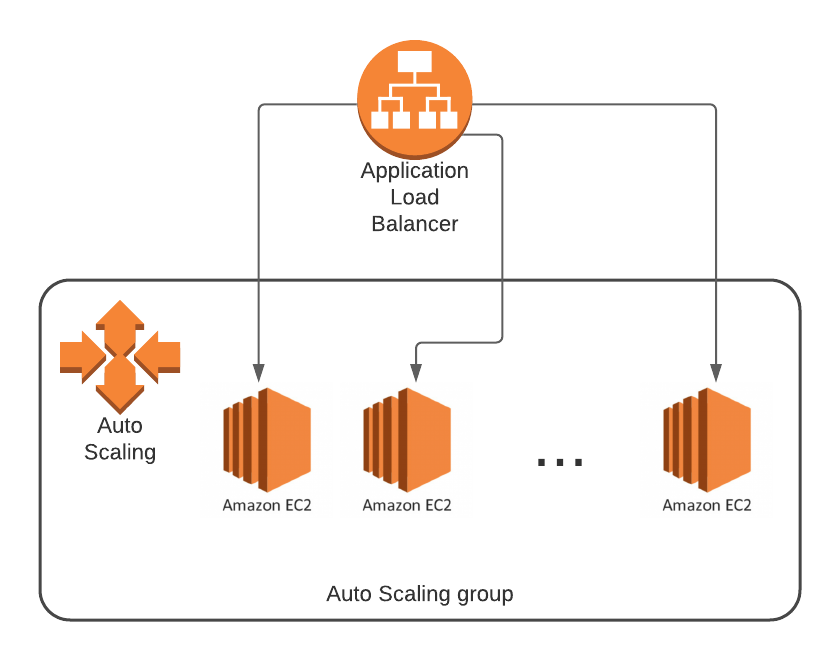
As mentioned above, scaling is really useful for reacting to changes in demand and allows you to have only the resources you need available when you need them.
This is achieved using Auto Scaling Groups, which allow you to set a minimum number of servers to have running, a maximum you don't want it to go beyond, and a flexible desired number, which changes based on your setup.
An example would be:
The numbers refer to Min/Desired/Max
2/2/4 Normal Scaling policy for 6pm, scale down to 1/1/2 Scaling policy for 8am, scale up to 2/2/4
Scaling would be set at 80% of CPU, so that when one server hits that threshold, another server is started up to help take traffic. You could then have the minimum scale down be at 20%, so that once the traffic has evened out, you drop a server as it is no longer needed.
This allows you to scale down at night and scale up in the morning (it's recommended to scale up before you would normally expect traffic to allow your servers time to start up and be ready to go. So if you normally see traffic spiking at 9am as people start to login, then it's good to scale up at 8 / 8:30).
You can also use Auto Scaling Groups to span across multiple Availability Zones, to give you more resiliancy if one Availability Zone has issues.
More Advanced Topics
Spot Instances
Normally when you create an instance, it's created as what AWS call an On Demand server. This level of server has a specific cost associated with it (this can be reduced by Reservations or Savings Plans).
However, there is another method called Spot Instances, which allows you to request a server at a specific lower price (up to 30-50% lower usually). However, these are only available for a shorter time, at up to 6 hours. They can also shut down depending on circumstances (the price of the type of instance you want may have exceeded the maximum you are willing to pay), so you may lose the specific instance you are using. You do get a notification before they shut down so you can finish what you are doing, but this is only sent out 2 minutes before shutdown.
I would not recommend Spot Instances for customer facing tasks such as a web server or anything that cannot be interrupted, but they are perfect for tasks that can be stopped and started without issue. Tasks that run overnight for example can be made to run on spot instances so you minimise your costs overall.
Capacity Reservations
A Capacity Reservation is a way of ensuring that you are able to launch a specific instance type when you need it, as sometimes AWS can hit limits where there aren't any of a specific type available in your region. Using a Capacity Reservation allows you to reserve a set of specific instance types for your use.
This can be beneficial, but you need to ensure you launch these instance types during the time you have requested them as you will be charged for them, even if you don't actually run any.
Lifecycle Manager
The EBS Lifecycle Manager is an automated backup procedure for creating snapshots of your disks that you have attached to EC2 instances.
This allows you to back up all volumes that you have tagged in a specific way at a regular interval (or multiple intervals).
You can use Lifecycle manager to back up just the drives, or create an AMI from the instance and the attached volume.
Placement Groups
Normally when you launch multiple instances, AWS tries to spread out where you launch them, to minimise the chances of one failure affecting multiple of your instances that are running on the underlying hardware. However, in some cases this might not be beneficial to your application. For example, if you have machines running together that need low latency communication, then having them on machines that are physically close together is beneficial.
Placement Groups allow you to influence where your instance are created. Clustering allows your instances to be close together in the same Availability Zone. Partitioned is where smaller groups of instances are grouped together and separated from each other. Spread is where each instance is separated so that they don't share the same underlying hardware.
More information is available here https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
This concludes my EC2 Intro to AWS section. I will work on further areas to discuss, and will likely have individual posts covering some areas of EC2 in more depth.



