Elastic Compute Cloud: EC2 (Intro to AWS Series)

Professional Services Team Lead
AWS Solutions Architect
Well Architected Team Lead
Certs:
AWS Certified Solutions Architect - Professional
AWS Certified DevOps Engineer - Professional
AWS Certified Solutions Architect – Associate
AWS Certified Developer - Associate
AWS Certified Cloud Practitioner
ITIL v3 Foundation
SVQ 3 Management
Introduction
This post is part of my Intro to AWS Series and we will start off where many people start with AWS, with EC2, the main way of running virtual instances. This post will be on the long side, as I'm still experimenting with the best format for these. I've split this into 2 parts as it got a bit on the long side. I will also do a deeper dive into VPCs in a future post.
Let me know if this longer format works for you or if you would prefer one cover post and links to individual pages. I'd also appreciate some feedback on places where I've went over or under on the detail.
Some topics covered here are wide-ranging and knowing where to stop has been an issue even just in planning this topic. For example, when I'm talking about deploying EC2 instances, I could have veered off into Code Pipeline, Code Deploy, OpsWorks and many more services just for that aspect of EC2, however I will try to keep this contained to EC2 and explore the other topics in their own dedicated posts.
Some areas of EC2 will have a light overview here, and I will go into deeper detail in future posts. VPCs will be one of these, as I'll be covering the basic uses in EC2, but there are so much more areas to cover.
What is EC2?
Elastic Compute Cloud (EC2) is AWS's main "compute" service. By this I mean it is a service that runs virtual instances of varying different platforms and applications. I'll go into a lot more detail in the following sections, however think of EC2 as spinning up a server. Whether that is Windows, Amazon Linux 1/2, Ubuntu, CentOS or many other variations. You can set these up from scratch using a recently updated Image with the latest version and all patches, or a specific supported version.
EC2 also underpins a lot of how AWS runs other services. They use the same basic concept of running a virtual machine on host hardware at various other levels. Some of these are managed by the end user, some are managed by AWS. As an example, ECS, the Elastic Container Service for running Docker containers and tasks runs the actual instances that the containers run on through EC2.
Use Cases
EC2 is one of the more flexible offerings from AWS. (I'd say Lambda is another one that is very flexible). At its core, EC2 involves running some a virtual image on host hardware. You can run a lot of different operating systems, and you can use the vast majority of applications in this way. EC2 is one of the common fundamental building block of applications, and likely to be the closest analog for traditional data centre based computing, with some significant benefits. There are other application and infrastructure models such as serverless computing and microservice architecture that can use a combination of other offerings from AWS such as ECS / Fargate, Lambda or API Gateway and still include EC2 instances.
The combinations and possibilities are endless. We all need to start somewhere and EC2 is such a fundamental and commonly used area of Applications Deployment onto AWS that it is a natural staring point.
Main Topics

Elastic Compute Cloud (EC2)
As mentioned above, EC2 is about running a virtualized image on host hardware that AWS runs. You take something packaged up into an image. These are usually from amazon, but as we'll see in Part 2, making your own is a large part of the life-cycle. Commercial offerings are also available from the Marketplace with a vast array of different setups and pre-configured software).
While you are running the instance, it will run on the same bit of hardware at AWS's end, however this will be on a shared rack with other instances (yours and other customers) with no access between them. Whenever your instance stops and is restarted (by you manually or automated using scaling or time based policies - more on these later) then the underlying hardware you are running on will change. You will also occasionally get this on long running instances as well where you will get an email from AWS if the underlying hardware has an issue or is degrading and you need to move to another host. This is as simple as stopping and starting your instance. This doesn’t happen often, but if you keep an instance running for years, you will see this issue.
Below is a basic EC2 diagram that shows some key elements required for an EC2 instance.
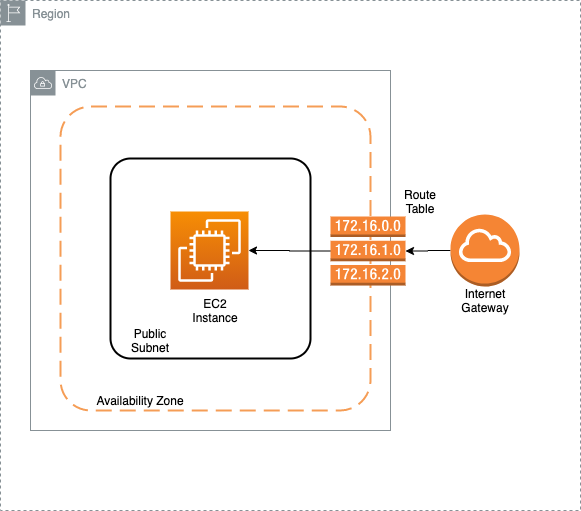
There are variations that I will go over (such as Private vs Public subnets, Nat Gateways in addition to Internet Gateways), but these are the basics required for an EC2 Instance.
Virtual Private Cloud (VPC)

One of the key concepts for using EC2 instances is to realise that a lot of what was previously built-in or part of the setup for an on premise / traditional setup is separated out in AWS (and cloud computing in general). This separation can initially be confusing to navigate and figure out what each element is used for, however it also provides for a lot of power and flexibility.
A key component in AWS is the VPC. This is a virtual private cloud, where you can deploy resources into. This applies to EC2 instances, which require one, but VPC's are ubiquitous across AWS, such that they have their own section in the menu.
I will cover VPCs in more depth in a future entry in the series, but hope to give you a high level understanding of their usage in this post.
One of the best ways to think of VPCs is to imagine them as a fence surrounding your resources. A VPC allows you to gather related infrastructure into logical units and have separation to control the flow of information between elements in your setup. You initially may just have one or two VPCs setup to hold some separate infrastructure, but as you grow, you will use more and more VPCs. There are ways to allow for traffic between VPCs that allow for control of the flow of information between your different components in a way that is structured.
A key principle of good design is to follow the practice of least privilege. This applies to more than infrastructure setup, and is frequently used in user permissions but it's also a good lesson to learn when setting up VPCs.
Least privilege means only giving access or permission that is specifically required for the purposes you need. In terms of VPCs this means organising things in such a way that your instances only have access to other resources and the internet where they need it.
As an example, if you have a basic web server and a database set up, it's good practice to have your web server set up so it can have outbound access to the internet, but only inbound access on ports you need open. This typically includes 80 and 443 for http and https, respectively. With the database you typically don't want external users to have direct access, so you set it up so that the only allowed connections are from your web server (or related instances) and only on the database port, such as 3306 for MySQL. This allows you to restrict the access to the database to sources you control.
There are other areas where you add other layers of security to the components, providing defence in depth to your resources.
Regions
AWS has a large number of data centre locations around the world. The way they organise these is into regions. An area of the country or continent might have multiple regions. The ones I mostly use are eu-west-1 (Dublin, Ireland) and eu-west-2 (London, England). It's best to choose a region close to where your main traffic is coming from, which in most cases will be the country you are in or a nearby country.
AWS rolls out features to regions separately, so that is something to keep in mind when designing your infrastructure. Dublin for example will typically get additional features and product launches before some other regions such as London or Frankfurt.
It's worth checking the region availability list for the features you are using before deploying in a region.
Availability Zones
AWS further splits regions into different Availability Zones (AZ) to provide for resiliency and availability. Most regions have a minimum of 2 zones, with some having 3 and I believe Asia Pacific (Seoul) is the only current one with 4. (There is also a local AZ for Los Angeles that is specific to use cases such as AWS Wavelength the 5G deployment product.
Each AZ has a letter after the region name to define it. So Dublin, eu-west-1 has 3 AZs. These are eu-west-1a, eu-west-1b and eu-west-1c
It's good to think of the AZ's as separate data centres but one quirk to this is that not everyone's AZ is the same. They allocate each account to a random data centre within the region for their reference to an AZ. So one account might have their eu-west-1a in a specific data centre, but another account the eu-west-1a AZ will point to a completely different data centre.
This isn't something that will overly affect you day to day, but it is worth using at least 2 AZs where possible to provide High Availability in case there is an issue in a specific data centre. The reason AWS does this is to stop overloading a specific data centre as it's a quirk of human nature that most people will chose the first one in a list if there isn't anything to differentiate the options, so to stop the first AZ in each region getting overloaded, AWS spreads the accounts out evenly.
Subnets
Along with VPCs, subnets are a useful way to organise your resources. A subnet defines the range of IP addresses that your instances can be given. These can be thought of as another smaller fence to separate resources further inside the main VPC fence.
Each instance is deployed into a subnet, which gives it the range of addresses it can take up. This is done through a CIDR range. This is an IP address with a mask at the end to provide a range that it applies to.
This is a good video explanation of CIDR Ranges: https://www.youtube.com/watch?v=u13AdjAUNmA
If you just want one IP range, then a /32 at the end defines this. So 10.0.0.1/32 refers just to the IP 10.0.0.1. As you go lower on the mask part, the numbers refer to a larger range, so 10.0.0.0/28 refers to the 16 addresses from 10.0.0.0 to 10.0.0.15.
There are several tools to work out the addresses. I like https://www.ipaddressguide.com/cidr and https://cidr.xyz/
At its most basic you can have 1 subnet in 1 VPC, but it's worth considering more.
You will come across the concepts of private and public subnets when setting up resources in AWS. These are essentially both just subnets with no difference in the actual subnet itself, but are defined by their uses. A private subnet is one which doesn't have direct access to the internet via an Internet Gateway (more on those later). A public subnet has a direct attachment to an Internet Gateway allowing instances deployed in it access to the internet.
Typically, where you want external users to connect directly to your instances, such as when running a web server, you would deploy these in a public subnet. Where you don't want users connecting directly you use a private subnet. A NAT gateway is used where you still need your instances to connect to the internet themselves (such as for package updates or operating system updates) but don't want anyone externally connecting in.
Internet Gateway

As mentioned above an internet gateway is the way your instances connect to the internet.
An internet gateway is a managed device from AWS. You provision one from the console (this is in the VPC section), and attach it to your VPC and give it a name and some tags to identify its usage if required.
AWS manage the actual instance and software themselves and they are set up behind the scenes as highly available (so at least 2 AZs etc).
You control which of the subnets within your VPC allow the instances in them to route through the internet gateway through a route table.
Network Address Translation (NAT) Gateway

A NAT Gateway's purpose is to translate traffic from instances that don't have a public IP Address through to the internet by providing them a route through the NAT instance to the Internet Gateway, and then to the Internet.
If you have your infrastructure set up with private subnets, where you have instances that only have private IP addresses that could normally only talk to other instances on the same network, a NAT Gateway allows you to route traffic from that instance out to the internet to allow for the instance to initiate a request for a connection.
By hiding it behind the NAT Gateway, connection requests in the other direction from the internet aren't allowed. From the outside, the only thing that is visible would be the NAT Gateway itself, there would be no way to know what instances are behind it.
This allows you to control access to these instances, while still allowing for access for the instances themselves out to the internet, most commonly for updates for the operating system and packages.
You can also use a NAT Instance, which is an EC2 instance where you control the setup rather than AWS managing it. However, even though there is a slightly higher cost associated with the NAT Gateway version, I recommend using the managed service over the NAT Instance setup.
Route Tables
Route tables are used in AWS to tell resources what address ranges they are allowed to access and where to go for that information. Each route table is attached to a subnet to provide information specific to that subnet about what its rules are.
All subnets get an initial route table setup with one entry. It will contain the subnet's IP range and a target of local. This means that if you have multiple instances and they want to talk to each other, the route table will tell them to just stay on the local network.
Route tables are also used to allow access to NAT Gateways and Internet Gateways. In both instances the entry in the route table will have 0.0.0.0/0. This is just shorthand for all addresses. The route tables are in priority order, so any local traffic will be dealt with first, then anything remaining will be routed to the all address.
This is an example of a public subnet with an Internet Gateway attached.
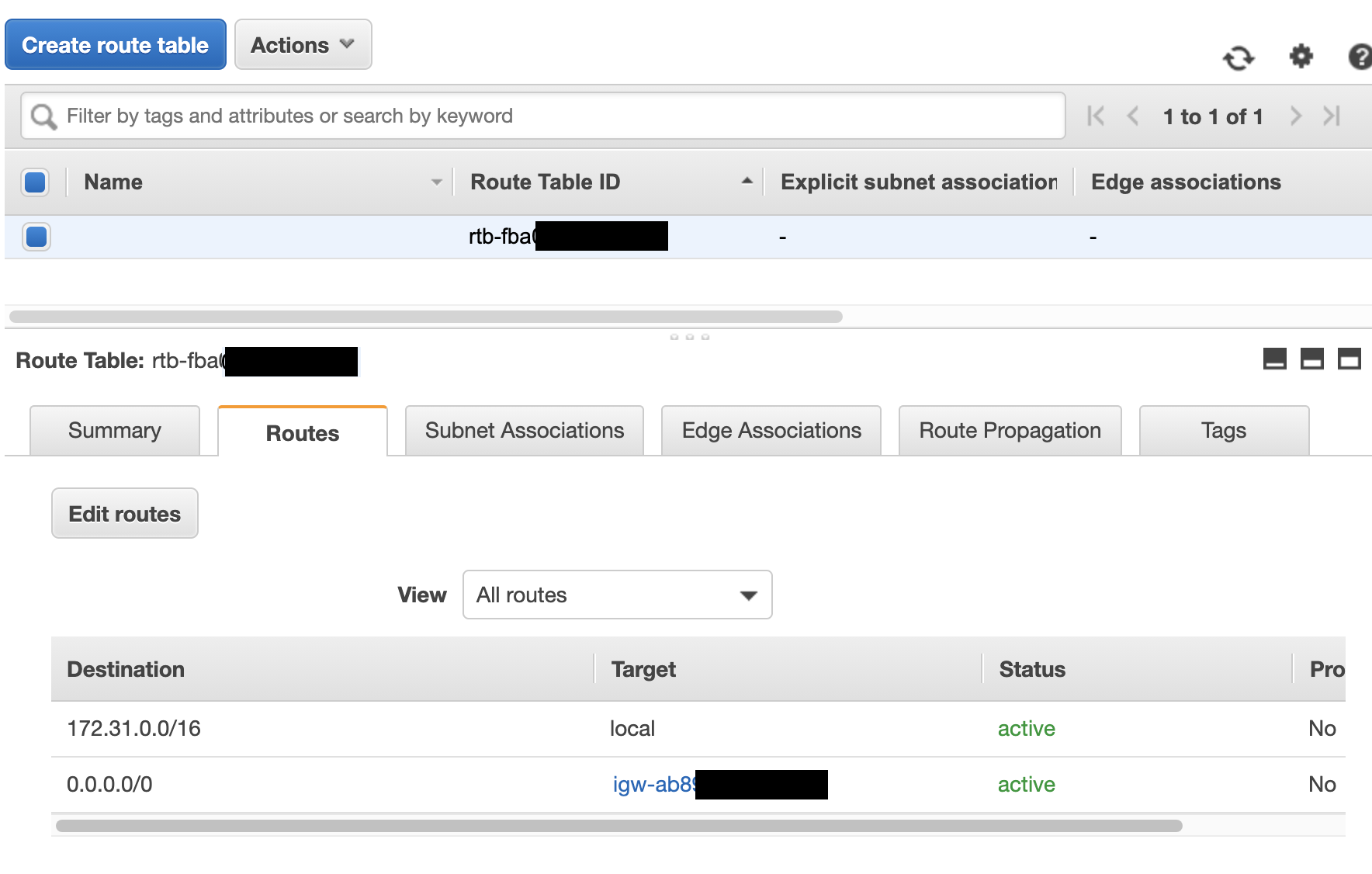
The target for Internet Gateway is the igw-randomstring address. NAT Gateways show up similarly with their own ID.
Route tables have a lot more usage, for things like Transit Gateways, VPC Peering etc that I will cover in the future, along with more advanced VPC topics.
Security
This last (for now) section will cover two aspects of setting up EC2 instances that are very important, covering some security aspects specifically relating to access to your resources for traffic. There are other aspects you need to consider such as user permissions that will be covered in future topics.
There are 2 ways to allow and restrict traffic. These are Security Groups and Network Access Control Lists.
Security Groups
Security Groups are a key part of the AWS setup. They are used to control access into your resources and access out.
This is where you decide what range of addresses are allowed in and what ports or protocols they can use. You can also allow for access from other Security Groups, which is a useful way of chaining your access together so that you can set up access to only be allowed into one area from another that has a specific security group attached.
So, for example, you could have a "Database Access" Security Group and apply that to multiple different private subnets that require database access, then on the database you just need to say that access from that security group on your database port is ok.
This allows you to have multiple entry points for the database without having to change the rules on the database's security group. Just attach the right Security Group to each subnet and it will be allowed to access the database.
For a web server the most common setup is to allow for incoming access on port 80 and 443 for applications such as Apache and Nginx for http and https traffic over TCP.
One key concept to be aware of is that Security Groups are Stateful. Security Groups have separate Inbound and Outbound rules governing what the resources it's attached to can access, but when a request comes in, the rules it used on the way in are remembered and attached to the traffic as its state.
So if you allow access to an instance on port 3306, then when the traffic is on the way back out it will be allowed out, regardless of what the outbound rules say. The outbound rules are typically used to lock down just what the instance itself can access from connections it creates.
Network Access Control Lists (NACLs)
Network Access Control Lists (NACLs) are another way to control traffic, but the difference here is that NACLs are stateless, so their Inbound and Outbound rules are applied separately. NACLs also provide a list that is evaluated in order and an accept or deny can be provided at each step. This allows for layered rules to be set up, rather than just the single entries that are matched in the Security Groups.
Both Security Groups and NACLs are evaluated when traffic is being routed so they can be used together. The primary use of NACLs I've seen is to deny specific IP addresses while the Security Group handle the main access requirements for everyone else.
One thing to note with NACLs is that once you get past about 10 entries, there is a bit of a delay introduced as all of the rules are evaluated in order, every time traffic is routed through, so it's recommended to use them sparingly.
Part 2 (Coming Soon)
This post is already on the long side, so I will cover more topics in a second part. Part 2 will cover:
- Amazon Machine Images
- Instance types
- Networking & Security
- Key Pairs
- Network Interfaces
- Elastic IPs
- Storage
- Elastic Block Storage (Ebs Volumes)
- Snapshots
- Load Balancing
- Load Balancers
- Target Groups
- Scaling
- Launch Configurations
- Auto Scaling
- More Advanced Topics
- Spot Instances
- Capacity Reservations
- Lifecycle Manager
- Placement Groups
Useful Links
EC2 Instance Info Very useful for comparing the (many) instance types for specifications and costs.
CIDR Range Lookup
https://www.ipaddressguide.com/cidr and https://cidr.xyz/ https://www.youtube.com/watch?v=u13AdjAUNmA




